服務器運維技術 埃里克·施密特:云計算中的霧計算和邊緣計算

2006 年,CEO Eric Sc??hmidt 首次提出云計算(Cloud)的概念。 2011年,哥倫比亞大學教授提出霧計算(Fog),后來被思科理論化。云計算是集中式計算,埃森哲()給出的云計算定義:第三方提供商通過網絡動態提供和配置IT功能(硬件、軟件或服務)。
霧計算是云計算概念的延伸。它是局域網中的一種分布式計算方法。符合互聯網“去中心化”的特點。獨特的應用特性使得這種計算范式支持更多的邊緣節點。
2011年,邊緣計算(Edge)的概念同時出現。社區給出的定義是:邊緣計算是在網絡邊緣為應用開發者和服務提供商提供云服務和IT環境。旨在提供接近數據輸入或用戶的計算、存儲和網絡帶寬的服務。
霧計算與邊緣計算的區別在于霧計算具有層次化、網絡化的架構,而邊緣計算依賴于不構成網絡的單個節點。霧計算中的不同節點具有廣泛的點對點互連能力,而邊緣計算是一個運行在孤島中的節點,這些節點被容納在云或霧網絡中以實現流量傳輸。
云計算、霧計算和邊緣計算是三種不同但相關的計算范式,每一種可能對數據庫系統有不同的要求。如今,云計算中的云數據庫的特性基本得到驗證,但也在不斷發展。霧計算中霧數據庫的特點尚未被提出,邊緣計算中的數據庫是否可以從傳統的單機數據庫系統中稍微演進一些也沒有被提及或討論。
但是,三種不同的計算方式必須適用于不同類型的應用,對數據存儲、管理、計算和交換的要求也必須不同。深入研究不同應用的需求和特點,提供不同類型的數據庫。未來數據庫的種類或形式一定會更加豐富多彩。

01 云原生
Cloud的概念早在云原生的概念之前就出現了,其內容可以概括為一種方法論,稱為12- (12-App)。根據這12個要素,人們對數據庫提出了如下一些具體的要求,使數據庫的結構和功能發生了變化。
Matt Stine 在 2017 年的一次技術會議上的分享中提出了“云與微服務:一種共生關系”的概念,云原生(Cloud)的概念正式誕生。他將云原生分為六個特征:模塊化、可觀察、可部署、可測試、可替換和可處理。
Matt Stine 認為:服務的基本原則是有明確的重點(應用功能細分的要求)、明確的契約(應明確定義應用與后臺服務之間的接口)、明確的 API(應用程序與后臺服務之間的接口在形式上應清晰易用)。
云原生一般被認為是思想的集合,包括很多東西:、持續交付()、微服務()、敏捷基礎設施(Agile)、康威定律(Law)等,并根據公司重組其商業能力。
這使得云原生的概念全面而復雜,它是一系列技術、企業管理方法的集合,既包括技術(微服務,敏捷基礎設施),又包括管理(從,管理技術在持續的層面上)交付、康威定律和重組)。
云計算改變了傳統的應用模式,其自身特點如下。
1.縮放
IT 設施正在從分散式轉向集中式和大規模。大規模數據中心作為基礎設施大量建立,為全社會提供集中服務。
2.資源池
IT設施規模化后,硬件資源需要根據彈性業務的需求進行統一管理。業務規模要具備動態、瞬時的伸縮能力,所以要集中硬件資源,提供彈性服務。
云計算有望通過互聯網為用戶提供按需的IT資源服務。因此,云服務提供商必須確保在提供的硬件資源上擁有足夠容量的資源池,以確保在并發業務高峰時段滿足用戶的服務需求。這就是云服務的資源池化。
作為一種服務,云數據庫類似于云計算,它可以管理和使用的資源也需要資源池化。這樣,用戶在使用云數據庫服務時,不需要了解云數據庫中的實際架構和技術實現,用戶感知到的就是自己使用的獨立完整的數據管理服務和相應的計算資源。

對于用戶來說,資源管理作為多租戶特性體現在云數據庫中服務器運維技術,根據租戶租用的資源提供服務。將數據庫內部資源池化后,可以為用戶應用提供彈性伸縮服務。
3.面向服務
云計算改變了 IT 行業過去可以提供的服務。
4.多元化
數據形式和應用場景由簡單化向多樣化轉變。服務、微服務等已經成型,()作為一種FaaS(-as-a-)也開始為世界的多樣性和興奮做出貢獻。

02 云數據庫
為了滿足云應用的研發需求,在云上提供服務的數據庫系統也相應發生了一些變化。云原生數據庫是指通過云平臺構建、部署、交付和自動運維的數據庫服務。
該服務通常采用DBaaS(-as-a-)的形式,隱藏了數據庫架構和實現細節,以多租戶和高效資源分發的形式自動管理云資源,為用戶提供A滿足彈性伸縮、高可用、高可靠、高安全、強一致性要求,隨時隨地可訪問的數據庫服務。
該服務具有自動化運維能力(需要很少的人力),可以提供自動備份恢復、自動性能調優、大型數據庫集群的自動資源調整等。工作(具有智能數據庫的特點)。該能力降低了云數據庫系統托管和維護的成本,并大規模提高了資源利用率。
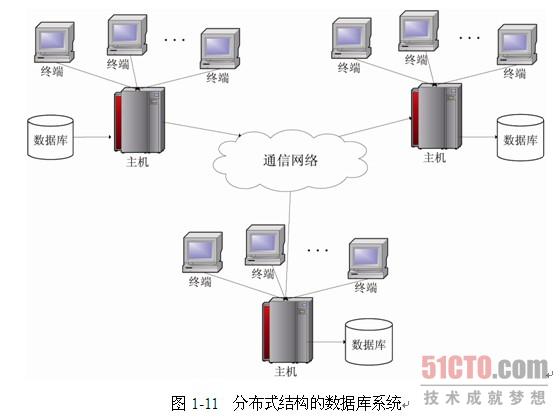
總的來說,云數據庫的特點可以概括為解放用戶和適應業務。具體可以轉化為以下6項,其中前3項屬于解放用戶類,后3項屬于適應業務類。
1.智能運維(智能數據庫)
故障可以自愈,包括停機自動遷移、故障隔離、異常流量自動調度、負載均衡、自動限制流降級等。數據庫可以自動調優,自動調整資源使用,有自適應算法,以應對應用程序的負載等。這些能力可以概括為自調優、自適應、自動駕駛(業界將自動駕駛的標準分為6個級別,數據庫社區借用這個級別來定義數據庫自動駕駛的概念)。
2.易于管理
智能運維的性能易于管理。云數據庫具備異常自動分析診斷能力,可實現白屏、智能化、規模化、少人化運維操作。
3.極致體驗
用戶可以以最簡單的方式完成數據庫的申請、創建、監控、報警、故障定位,給用戶帶來極其便捷的體驗。
4.彈性伸縮
可根據業務應用負載自動伸縮,具備秒級擴縮容能力,靈活動態分配或釋放資源,結合靈活計費策略,可大幅降低用戶使用成本。本文部分內容與智能運維有重疊,但描述問題的角度不同。本文從系統可擴展性的角度描述了云數據庫的重要特性。
將業務或系統遷移到云端就是購買應對未來的可能性。對于商家在業務發展過程中,隨著數據的積累,存儲可以隨時在云端擴展,計算節點也可以自由擴展。這是商家從小到大的最佳資源利用。方法是最便宜的方法。
支持這種業務發展的技術是彈性伸縮。在彈性伸縮中,需要考慮事務執行的順序。對于數據庫架構來說,這個順序就是存儲和計算的分離。
5.按需計費
支持設置多個按量計費(如流量、存儲、調用次數、調用時長、內核數、內存資源使用量等)。這種定價策略可以讓用戶根據業務情況靈活匹配最優的計量模式,節省用戶成本。
6.安全和資源隔離
云數據庫采用共享池化技術,提高計算、存儲、網絡等資源的利用率,隔離用戶并發爭用資源。此外,提供多租戶方式,實現安全隔離,避免信息泄露或攻擊。
以上內容為云數據庫的設計指明了方向。

03 數據庫
它是一種無服務器架構,它不是一個特定的編程框架或工具,而是一個軟件系統架構思想和方法的核心思想是讓用戶不需要關注支持的底層主機應用服務的運營。用戶可根據應用需要,按需使用底層服務器(硬件和軟件系統),按使用量付費。此類應用所需的計算資源由底層云計算平臺動態提供。
云原生數據庫作為后臺服務,提供了一種數據庫服務/訪問方式來連接用戶,這個方式就是方法。但是,它不僅是一種連接數據庫的服務方式,也是一種連接其他類型服務的方式。是云數據庫的服務能力。云數據庫將數據存儲、管理和計算能力轉化為服務,為用戶提供服務。
一個有能力的數據庫系統需要在存儲層面解決無限的數據存儲能力;在計算層面,需要提供彈性計算能力;在內部系統架構上,需要提供監控和調度能力。資源分配可以動態進行;對于數據庫的每個組件服務器運維技術,都必須具備被池化的能力,即具備自動管理資源的能力;對于用戶訪問層,必須能夠響應用戶訪問事件請求,根據訪問量,利用前述的存儲、計算、管理基礎彈性伸縮,應對應用層的峰谷,并按體積收費。
如果云數據庫具有無服務器架構的能力并支持依賴于數據庫類的應用程序,則可以調用它。在構建能力時,云數據庫應具備以下特點。
圖 6-1 展示了 AWS 的功能。
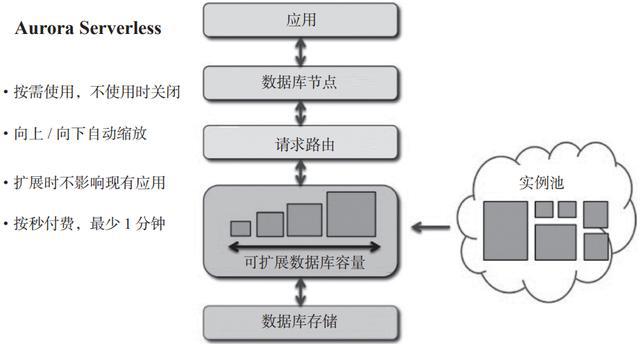
▲圖6-1 數據庫有能力
在應用層,可以以函數或事件的形式進行連接。進入服務平臺。比如AWS API接口會觸發AWS函數或者函數,這些函數會從數據庫表中獲取數據流,返回應用時數據的格式是固定的。不同的云計算廠商有不同的設計方案,但使用的思路是相似的。
作者簡介:李海翔(網名:),騰訊金融云數據庫首席研究員,騰訊T14級專家,騰訊TDSQL分布式數據庫首席架構師。中國人民大學、北京林業大學特聘碩士生導師,CCF數據庫專委會委員,DTCC(中國數據庫技術大會)專家委員會委員,北京市科技進步一等獎獲得者。申請并獲得專利70余項,在VLDB等數據庫會議上發表論文數篇,參與多項國家863重大項目、核高技術、工信部、科技部和其他項目。
本文摘自《分布式數據庫的原理、架構與實踐》,經出版社授權發表。

《分布式數據庫原理、架構與實踐》
推薦:騰訊T14級專家,騰訊金融云數據庫首席研究員,騰訊TDSQL首席架構師撰寫,從原理、架構、案例三個維度深度解析分布式數據庫。

 售前咨詢專員
售前咨詢專員
