無服務器架構下的運維日志默認與運維的四個維度
在介紹運維之前,我們先簡單了解一下()的概念。 由于筆者的實戰經驗是在AWS平臺上進行的,所以本文中的指的是使用AWS構建的應用。 特點是用戶不需要預先配置或管理服務器,他們只需要部署功能代碼,服務會在需要時執行代碼并手動擴展,從每晚幾個請求到每秒數千個請求,輕松實現 FaaS (asa)。 如右圖所示:
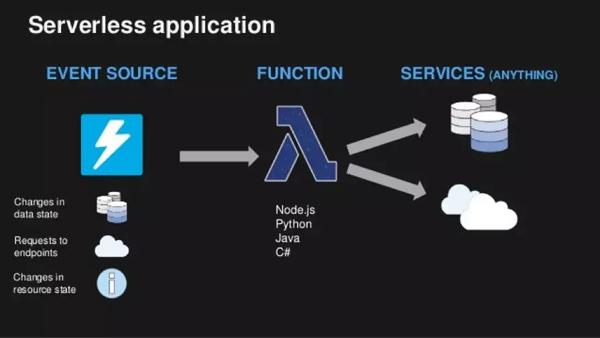
(圖片來自網絡)
在傳統的應用程序中,開發團隊不僅需要編寫功能代碼,還需要監控實時負載,相應地擴展應用程序,并處理一些非功能性故障(硬盤、內存等)導致的停機時間。 . 架構將開發團隊從維護服務器的工作中解放出來,讓他們可以更專注于功能代碼(如圖)。 在實際項目中,開發者只需要將功能代碼打包上傳到AWS,然后進行少量配置(環境變量、觸發條件、顯存、超時時間等)即可啟動應用/服務。
以上就是架構的基本概念。 接下來筆者將從日志、指標、監控上報、容災四個維度來介紹架構下的運維。
日志
默認情況下,應用運行時產生的日志會保存在應用服務器上。 當需要查看日志時,運維人員需要遠程登錄服務器獲取日志信息。 這些方法操作起來略顯復雜,但是當應用服務器數量增加時,查找日志的效率會嚴重降低,因為需要先找出導致錯誤信息的服務器。
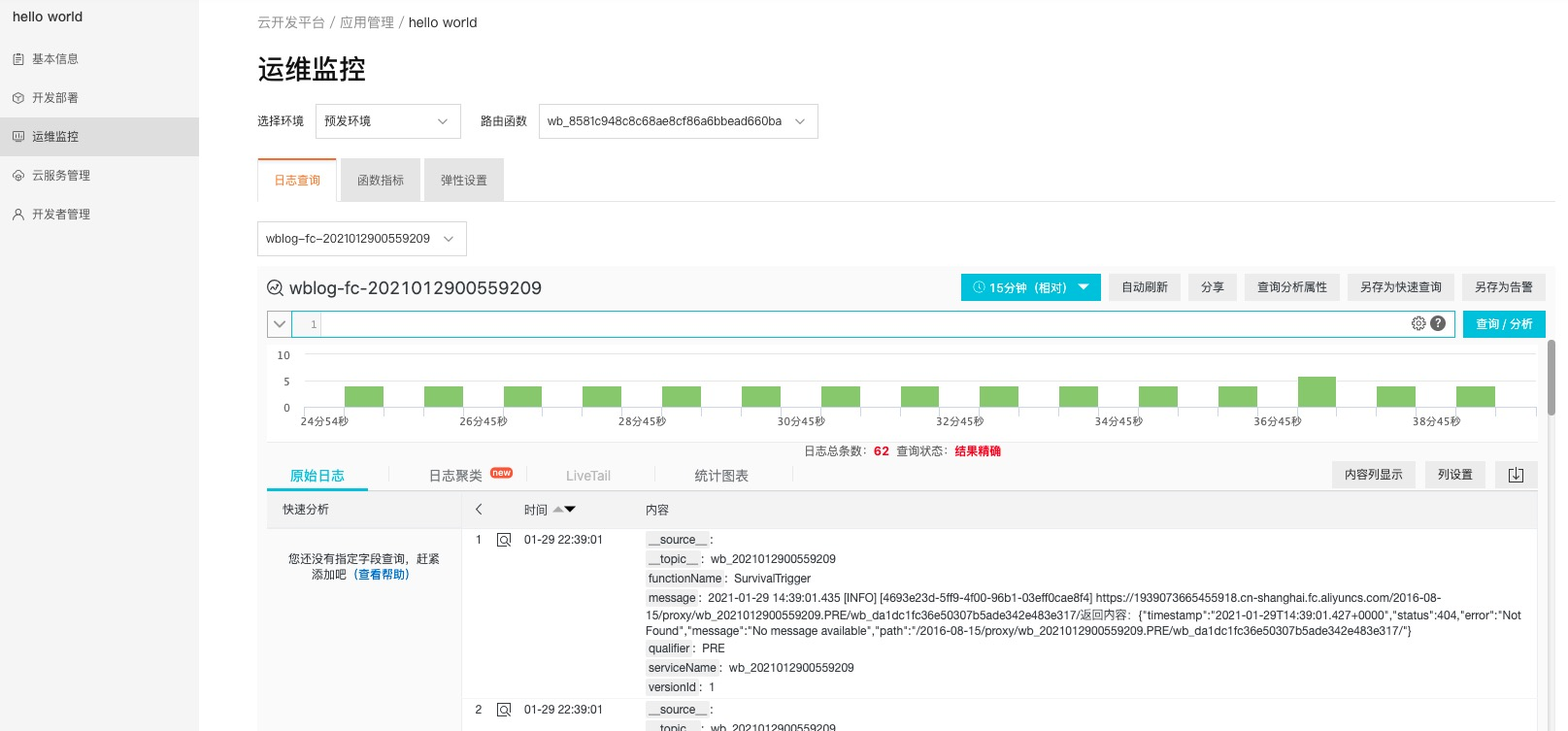
一種解決方案是 ELK(,,)。 這三個開源工具各司其職,負責日志推送和轉換,作為數據庫和搜索引擎,作為圖形界面。 優點是易于搭建,擴展性好,免費。 但額外的代價是,獨立的日志服務還需要做好全方位的監控(應用狀態、硬盤、網絡等),防止因為基礎服務問題導致系統徹底掛掉。
AWS 無服務器架構中的日志是一種開箱即用的服務。 所有日志都手動收集到 中。 您只需要根據服務名稱找到對應的日志組,即可查詢搜索,無需任何配置和維護成本。 .
指數
通常情況下,運維工作會包括收集線上應用的運行指標服務器運維技術,反映應用的健康狀況、故障率、性能、訪問量、訪問頻率等。 下面是一個使用Boot創建的API服務的例子,起到收集指標的作用。 在默認配置中,對于每個 API,將手動收集以下指標:
其實我們可以通過實現一些來擴展/自定義 ,這里就不展開了。 有了指標數據,還需要相應的報表或儀表盤工具,方便更好的查詢和展示。 您可以選擇像 .
那么AWS 架構有沒有提供類似的指標收集呢? 答案是肯定的,AWS人工采集了以下四個指標:
并取一段時間內的總量,兩者結合得到應用的錯誤率,如下
平均數用來反映一段時間內的表現。 在筆者的項目中,時長主要集中在SQL查詢上。 這個數字可以反映技術人員對查詢優化的有效性。 其實在實際情況中服務器運維技術,這種檢查是可以在預發布環境中進行的。 這個例子只是為了便于理解。
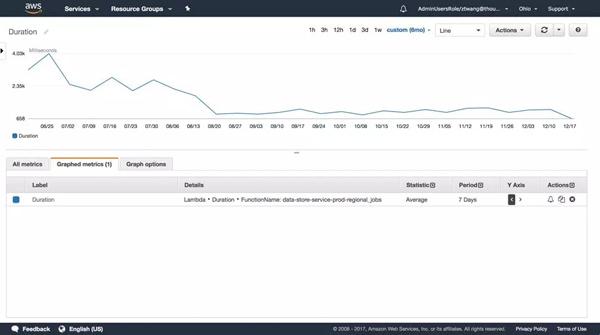
在筆者目前的項目中,并沒有使用到。 默認的并發限制是1000/s,最大劑量的調用頻率每分鐘只有150次,遠遠沒有超過限制。 但是,這個數據對于高并發的應用來說是非常重要的。
不僅開箱即用的幾個指標,還有可以組合的API,可以在相應的功能代碼中嵌入點數,以多種方式收集指標。 比如代碼中的一、三子任務,默認提供只能體現整體的運行效率。 如果需要統計每個任務的消耗,需要使用。
監控與報告
監控的意義在于全面了解應用程序的資源使用情況、性能和運行情況。 這些數據可以用來幫助團隊及時做出調整,保證應用的順利運行。 這一般包括CPU使用率、數據傳輸、C盤使用率等。當突發事件導致系統不可用時,團隊的響應速度往往取決于監控和報告的及時性、全面性和準確性。 如果能夠根據歷史數據的分析合理配置監控系統,團隊甚至可以預知壞事即將發生,提前未雨綢繆,未雨綢繆。
同上,這里以一個Boot應用為例,在上一節中提到了指標數據的收集,實際上不僅可以記錄其中提到的指標,還可以用來收集監控數據。 這里我們只需要搭建一個應用,在需要監控的應用中添加配置,監控數據就會通過暴露的API傳遞給。
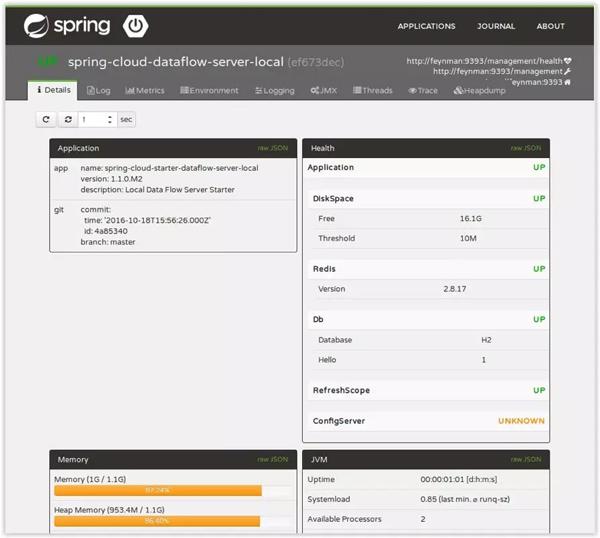
上報功能通常需要根據實際情況自行實現。 實現了Slack等第三方工具的集成。 如果只需要簡單的短信提醒,實現起來并不復雜,這里就不展開了。

隨著云上基礎設施的普及,上述的監控和上報已經是各個平臺的標配,如何實現和維護已經不是開發者操心的事情了。 運營團隊可以更專注于配置優化。 去工作。
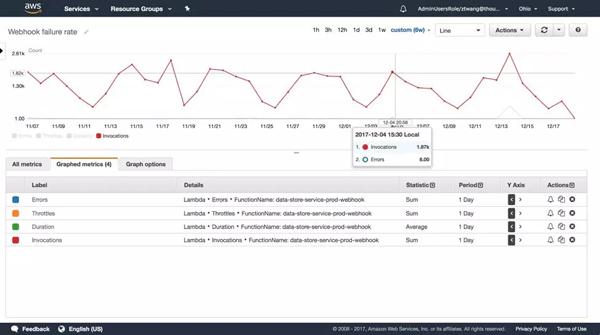
AWS默認提供了非常完善的監控數據,也允許自定義監控。 通過在創建的基礎上添加一系列重要的指標,可以一目了然的看到應用的運行狀態。
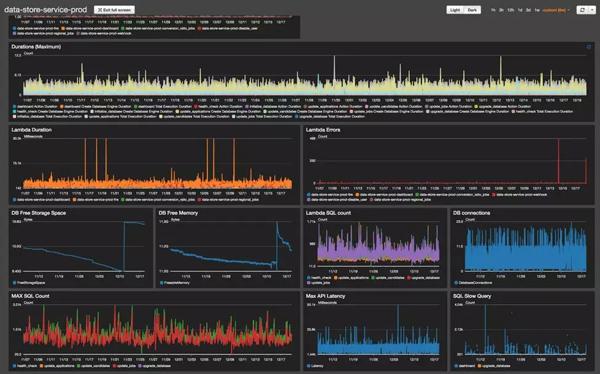
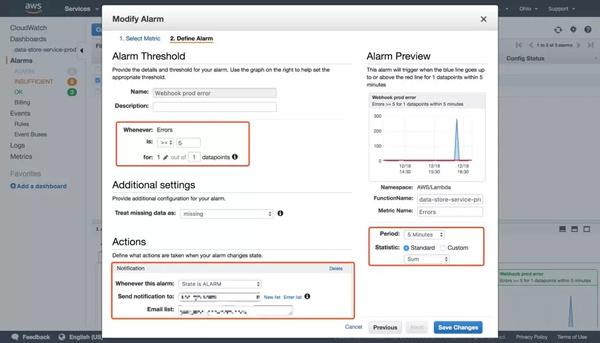
如前所述,當出現錯誤或性能下降時,需要根據各個關鍵指標的變化發送警告通知。 筆者的項目是利用AWS和提供的告警通知功能。 您只需要先選擇指標,然后設置觸發閾值和檢測間隔。 支持 HTTP、SMS、Email 等訂閱形式。 右圖顯示了如何設置在過去 5 分鐘內錯誤發生超過 5 次時發送通知。
災難備份與恢復
在系統鏡像、構建工具、容器技術越來越普及的今天,容災備份的意義很大程度上在于有效保護重要數據。 一般的做法是設置一些定時任務,將數據傳輸到異地的災備中心,從數學上抵御不可抗拒的災難。 如果數據量太大,網絡傳輸效率跟不上,可以參考AWS用卡車拉數據的方案。

真正需要使用容災備份的情況,筆者有限的經驗還沒有發生過,如果不提前做好打算,真正發生時的后果將不堪設想。 筆者項目中使用的默認開啟手動備份,周期為7天。 此配置可以自動調整或寫入腳本以構建基礎設施。 如果真的發生了災難,僅僅有數據備份是不夠的,還要能夠在應用程序運行時快速重建基礎設施。 作者團隊(以下簡稱團隊)分別使用AWS和重建了數據庫、網絡等基礎設施。 重建數據庫時,通過持續集成管道,將環境變量方法傳遞到最近一次。 數據備份快照Id,15分鐘內可重建產品環境。
總結
作者團隊是10人左右的配置,采用結對編程的方式,3對,包括web端、業務層、數據層。 從確定產品原型到首次上線(MVP)需要30天,每周至少發布一次新版本。 故事的平均交付時間(,從需求確定到發布)為8天。 這樣的速度顯然不算快,而且如果沒有運維端架構提供的支持,我們想要在交付速度上有更高的突破就難多了。
最后,讓我們談談成本。 俗話說,放棄商業化談技術是耍流氓。 大多數人在聽到功能強大且易于使用的工具時,都會下意識地認為成本會很高。 事實上,情況并非如此。 我們粗略算了一下,選擇了四核CPU、8G顯存的M4服務器。 費用是每月 72 美元。 Dev 和 prod 三個環境使用相同的配置,即每月 216 美元。 事實上,每月的支出包括所有環境,大約為 20 美元。 應該注意的是,計費是基于使用的。 我們的 API 訪問量大約為每月 150 萬次。 可以預見,當訪問量達到一定數量時,支出將等于甚至大于使用服務器的支出,而且在金額較小時優勢明顯。
得益于強大的AWS生態,只需極少配置或無需配置即可借助完整的應用,以極低的價格獲得完整的運維功能和體驗。 相比借助開源工具構建的形式,開發團隊可以從繁瑣的運維工作——尤其是基礎工程建設中解放出來,更專注于產品本身,大大提高軟件交付率和易用性,可靠性和可擴展性也相當有保證。 換來的代價是更高的遷移成本,個別功能的不多樣化可能成為兩難選擇,底層實現原理的屏蔽也可能對開發者的學習和成長產生影響。
上一篇:服務器會選擇什么操作系統呢?

 售前咨詢專員
售前咨詢專員
